

Als Data Lake (zu deutsch Datensee) bezeichnet man ein umfangreiches Datenlager, in dem verschiedene Daten aus unterschiedlichen Quellen in ihren Rohformaten gespeichert werden können. Aufgrund der Menge an heterogenen, unformatierten Daten eignen sich Data Lakes hervorragend als Ausgangspunkt für geschäftliche Big Data Analyseverfahren. Data Lake Lösungen können lokal im Betrieb selbst eingerichtet oder im Cloud-Format von einem Online Service Anbieter gemietet werden.
Was ist ein Data Lake?
Ein Data Lake ist ein zentrales Datenverzeichnis oder Repository, welches die Ablage verschiedener Rohdatenformate in einer flachen Ordnerstruktur ermöglicht. In einem betrieblichen Kontext dient ein Data Lake beispielsweise der Speicherung aller digitaler Unternehmensdaten an einem Ort und kann sowohl von verschiedenen internen Abteilungen als auch externen Datenquellen befüllt werden.
Dadurch entstehen sehr große Datenmengen, die darüber hinaus noch besonders vielfältig und oftmals unstrukturiert sind. Aus diesem Grund sind bei der Auswertung von Datensätzen eines Data Lake meist Analysemethoden und -techniken aus dem Bereich Big Data nötig.
Zugleich dient ein Data Lake nicht nur als Speichermedium, sondern auch als Daten-Management-Plattform, welche die Verwaltung von Informationen mithilfe der im User Interface integrierten Tools möglich macht. Die in Data Lakes gespeicherten Daten lassen sich beispielsweise für die Einsatzbereiche Berichterstattung, grafische Visualisierung, echtzeitorientierte Analysen und Machine Learning einsetzen.
Verschaffen Sie sich effizienteren Zugang zu Unternehmenswissen und optimieren Sie die Kommunikation mit einem eigenen KI-Assistenten.
Data Lake vs. Data Warehouse
Neben dem Konzept Data Lake gibt es noch weitere Datenspeicherformate mit eigenen Strukturen und Anwendungsmöglichkeiten: das Data Warehouse, den Data Mart und das Data Silo. Von diesen wird das Data Warehouse am ehesten mit dem Konzept des Data Lake verglichen, da es einen ähnlichen Aufgabenbereich abdeckt.
Sowohl Data Lakes als auch Data Warehouses sind zentrale Speicherorte von Big Data, an denen Informationen aus unterschiedlichen Quellen gesammelt werden, um diese für Analysezwecke einzusetzen oder an unterschiedliche Anwendungen weiterzuleiten. Beide Formate werden gerne in betrieblichen Kontexten zur umfangreichen Datenanalyse eingesetzt. Doch damit sind die Gemeinsamkeiten der beiden Repository-Arten bereits ausgeschöpft.
Vergleicht man Aufbau, Datenstruktur, Zugänglichkeit und Nutzungsmöglichkeiten im Detail, werden die Unterschiede von Data Lakes und Data Warehouses schnell deutlich. In den nachfolgenden Abschnitten finden Sie eine Übersicht der grundlegenden Merkmale und Unterschiede von Data Lakes und Data Warehouses. Das dient der Veranschaulichung beider Konzepte und verdeutlicht, dass sie je nach Anspruch der geschäftlichen Datenverarbeitung gewisse Vor- und Nachteile haben können.
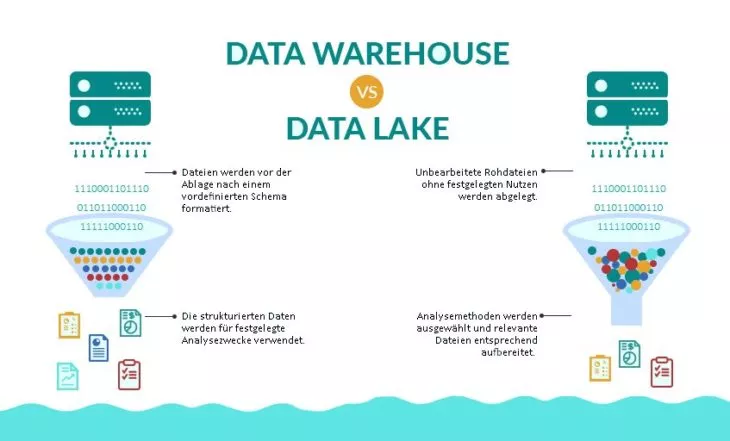
Datenstruktur: Schema-on-Read vs. Schema-on-Write
Data Lakes zeichnen sich dadurch aus, dass sie strukturierte, semistrukturierte und unstrukturierte Formate unterstützen. In einem Data Lake können also strukturierte Daten aus relationalen Datenbanken, semistrukturierte Daten zum Beispiel im CSV-, XML-, JSON-Format, aber auch unstrukturierte Daten wie Texte (E-Mails und Dokumente) sowie binäre Bild-, Ton- und Videodateien abgelegt werden.
Da die Daten vor der Speicherung weder validiert noch umformatiert werden müssen, spricht man im Fall von Data Lakes vom Ansatz des Schema-on-Read. Das bedeutet, die Dateien werden in ihrer Rohform gespeichert und erst dann, wenn es zur tatsächlichen Datenanalyse kommt, entsprechend den Prozessanforderungen strukturiert und formatiert. Das Gegenstück dazu wird als Schema-on-Write bezeichnet und entspricht dem im Data Warehouse eingesetzten Modell. Dabei werden die Dateien vor der Ablage bereits im passenden Format für den vorher festgelegten Auswertungsprozess aufbereitet und sind unmittelbar einsetzbar.
Ein Vorteil von Data Lakes ist dementsprechend, dass die Rohdaten sehr formbar sind, sich hervorragend für das Trainieren Künstlicher Intelligenz eignen und die Durchführung vielfältiger Analysemethoden erlauben. Auf der anderen Seite sind die aufbereiteten Daten in Data Warehouses speicherplatzsparend und ermöglichen eine mühelose Weiterverarbeitung.
Datennutzen: nicht festgelegt vs. vordefiniert
Entsprechend des Ansatzes Schema-on-Write dienen die in Data Warehouses gespeicherten Informationen stets einem vordefinierten Nutzen und müssen dementsprechend zweckmäßig strukturiert sein. Anders ist es beim Schema-on-Read des Data Lake, wo die Daten im Rohformat abgelegt werden und ihre tatsächlichen Einsatzmöglichkeiten nicht verbindlich festgelegt sind.
Da sich alle Rohdaten leicht zugänglich an einem gemeinsamen Aufbewahrungsort mit flachen Hierarchien befinden, lassen sich in Data Lakes besonders gut latente Zusammenhänge der verschiedenen Informationen erkennen. Darüber hinaus gestalten sich Organisation und Filterung der Daten dadurch weniger aufwendig. Das kann bei unsachgemäßer Datenverwaltung jedoch auch zur Folge haben, dass Data Lakes zu sogenannten Data Swamps (also Datensümpfen) verwahrlosen.
Data Swamp
Wenn bei einem Data Lake trotz steigender Datenmenge der Informationsgehalt abnimmt, befindet er sich im Transformationsprozess zu einem Data Swamp. Das kann beispielsweise passieren, wenn die gespeicherten Informationen wenig Wert für Business-Analysen bieten oder aufgrund mangelnden Metadaten-Managements schwer auffindbar sind. Aus diesem Grund haben Data Lakes einen hohen Bedarf an angemessenen Datenqualitäts- und Data-Governance-Maßnahmen.
Um dessen Versumpfung zu vermeiden und einen echten Mehrwert aus dem Data Lake zu schöpfen, bedarf es der regelmäßigen Entwicklung neuer Abfragen und Anwendungsmöglichkeiten auf Basis des Datenvorrats.
Benutzerfreundlichkeit: flexibel vs. sicher
Der Begriff Benutzerfreundlichkeit bezieht sich in diesem Fall auf die Verwaltung des Speicherverzeichnisses selbst, nicht auf die der darin enthaltenen Daten. Da Data Lakes aus simplen Strukturen mit flachen Hierarchien bestehen, sind sie allgemein leicht zugänglich. Aufgrund weniger Einschränkungen lassen sie sich darüber hinaus noch leicht und vor allem schnell modifizieren und skalieren.
Im Gegensatz dazu ist die Verwaltung der durchstrukturierten Data Warehouses mit deutlich mehr Kosten und Aufwand verbunden und erschwert die Modifikation bei veränderten Anforderungen. Allein die Einrichtung eines Data Warehouse kann sich als zeitaufwendig und komplex erweisen, da zunächst ein Datenschema definiert werden muss, an welches daraufhin alle Daten angepasst werden. Das steht einer flexiblen und direkten Nutzung entgegen. Allerdings haben Data Warehouses einen bedeutenden Vorteil, wenn es um die Zugänglichkeit der eigentlichen Daten geht.
Datenzugänglichkeit: komplex vs. einfach
Da in Data Lakes hauptsächlich unveränderte Rohdateien abgelegt werden, sind die für die Datenverarbeitung Verantwortlichen meist mit einer Vielzahl unterschiedlicher Datenformate konfrontiert. So können Datenströme aus Bild- und Textdaten, Protokoll-Dateien, Social-Media-Posts Sensormessungen, Click-Streams und vielen weiteren Quellen in den Data Lake fließen. Unerfahrene Benutzer sind mit der Analyse hier oftmals überfordert. Daher ist der Einsatz von Data Science-Experten gefragt, um relevante Informationen aus der Datenmenge zu filtern und diese konkret brauchbar zu machen.

Daten mobil und ohne festen Arbeitsplatz mittels Hardware-Geräten aufnehmen – das verspricht die mobile Datenerfassung, kurz MDE.
Hier haben Data Warehouses einen entschiedenen Vorteil: Aufgrund der vordefinierten Informationen im Schema-on-Write lassen sich die Datensätze stets nach ähnlichen Mustern bearbeiten. So kann die Datenbearbeitung durch einen größeren Kreis von Business-Anwendern ohne besondere technische Kenntnisse erfolgen. Diese müssen dann vorher lediglich einmal in die Verarbeitungsprozesse eingeführt werden.
Der Problematik von komplexen Datenaufbereitungsverfahren in Data Lakes kann mit entsprechender Vorbereitung jedoch entgegengewirkt werden. Es werden zunehmend , welche die Rohdaten selbstständig verarbeiten und Nutzern einen Self-Service-Zugriff auf relevante Informationen ermöglichen. So ist es dann auch für Laien möglich, mithilfe vordefinierter Verfahrensweisen aufschlussreiche Datenanalysen durchzuführen.
Ergänzender Einsatz von Data Lake & Data Warehouse
Trotz ihrer Grundfunktion als Speichermedien weisen Data Lakes und Data Warehouses durchaus verschiedene Strukturen auf und dienen ganz unterschiedlichen Zwecken. Unternehmer sollten mit den Einzelheiten vertraut sein, um eine fundierte Entscheidung treffen zu können, welches Format sich eher für die eigenen Geschäftsprozesse anbietet.
Da sich Data Lakes und Data Warehouses allerdings gegenseitig exzellent ergänzen, kann es sinnvoll sein, beides einzurichten. So kann der Data Lake zum Beispiel für die Verwaltung enormer Rohdatenmengen angewendet werden, während das Data Warehouse einen Teil dieser Daten aufbereitet und für gezielte Business-Analysen und Berichterstattungen einsetzt.
Tabellarische Übersicht der Merkmale:
| Data Lake | Data Warehouse | |
| Datenstruktur | roh (Schema-on-Read) | aufbereitet (Schema-on-Write) |
| Datennutzen | nicht festgelegt | vordefiniert |
| Datenzugänglichkeit | komplex (Experten) | einfach (Business-Anwender) |
| Benutzerfreundlichkeit | einfach & flexibel | kompliziert & eingeschränkt |
Data Lakehouse als Verbindungsstück
Während Data Lakes und Data Warehouses lange Zeit als getrennte Konzepte betrachtet wurden, hat sich in den letzten Jahren ein neuer Ansatz etabliert.Das Data Lakehouse verbindet die Flexibilität eines Data Lakes mit den Analysefähigkeiten eines klassischen Data Warehouses. Unternehmen können damit Daten nicht nur frei sammeln und speichern, sondern auch effizient für Berichte, Dashboards oder Machine-Learning-Projekte nutzen. Moderne Plattformen wie Databricks oder Snowflake bieten dafür integrierte Lösungen an, die Echtzeitanalysen, bessere Governance und Kostentransparenz ermöglichen. Das Lakehouse schließt damit die Lücke zwischen reiner Datensammlung und datengetriebener Entscheidungsfindung.
Data Mart & Data Silo
Beim Data Mart und Data Silo handelt es sich um besondere Formen von Datenverzeichnissen, die ebenfalls von Interesse sind, wenn man sich mit der Thematik von Data Lakes und Data Warehouses beschäftigt.
Data Mart
Ein Data Mart ist vereinfacht ausgedrückt eine Kopie oder Teilansicht eines begrenzten Bestandteils von Informationen aus einem Data Warehouse. Meist werden Data Marts für einzelne Organisationsbereiche oder Anwendungen eines Unternehmens und für ganz spezielle Datenanalysen eingerichtet. Dementsprechend sind sie für die Anforderungen einer bestimmten Nutzergruppe konzipiert und ihr Zugriff beschränkt sich auf ausgewählte Teilsegmente eines Data Warehouse.
Für die Nutzung von Data Marts sprechen mehrere Argumente: Zunächst wird die Geschwindigkeit der Datenabfrage deutlich erhöht. Darüber hinaus sind sie flexibler konfigurierbar als Data Warehouses. Wenn sich zum Beispiel die Anforderungen an einen Analyseprozess verändern, ist das Einrichten oder Umstrukturieren eines Data Marts wesentlich einfacher als die Modifikation der gesamten Data Warehouse-Infrastruktur. Weiterhin ermöglichen Data Marts die Abgrenzung ausgewählter Datenbestände von anderen Nutzern. So kann beispielsweise der Zugriff auf sensible Daten durch unautorisierte Personen gemäß Datenschutzrichtlinien verhindert werden.
Data Silo
Data Silos sind zugangsbeschränkte Speicherverzeichnisse, die im täglichen Gebrauch nur von einer einzelnen Abteilung oder einem einzelnen Mitarbeiter genutzt werden. Für den Rest des Unternehmens unzugänglich, können die dort verfügbaren Informationen nicht eingesehen oder für Analyseprozesse eingesetzt werden. Das hat oft zur Folge, dass der Aufwand für Informationsbeschaffung steigt und die interne Kommunikation ineffizienter wird. Weiterhin besteht die Gefahr, dass es durch unzureichende Datenpflege dazu kommt, dass veraltete oder gar falsche Informationen gespeichert werden. Schlimmstenfalls kommt es noch zu Bearbeitungsfehlern und die korrekten, aktuellen Daten werden überschrieben. Genau diese Probleme und Gefahren können durch die Einrichtung von Data Lakes und Data Warehouses vermieden werden.
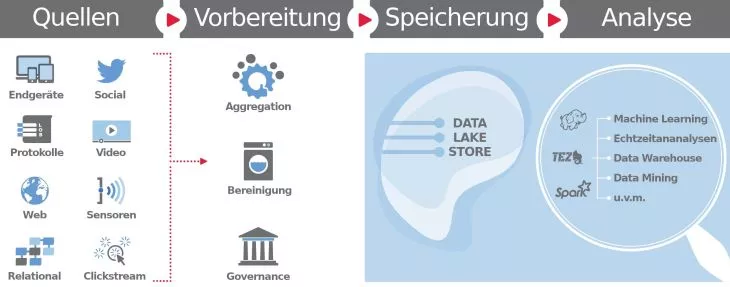
Nutzungsvoraussetzungen von Data Lakes
Die Architektur von Data Lakes erlaubt die Aggregation vielseitiger Datenformate – von vorstrukturierten Datenbanksätzen bis zu den maschinell erstellten, ungefilterten Echtzeit-Datenströmen aus dem Internet of Things. Datenanalytikern stehen unterschiedliche Analysetools und Frameworks für die Bearbeitung der heterogenen Datenmengen zur Verfügung, um beispielsweise Data Mining, Big Data-Analysen oder Machine Learning zu betreiben.
Die Flexibilität von Data Lakes hat jedoch ihren Preis: Um das reibungslose Zusammenspiel dieser komplexen Vorgänge zu gewährleisten, müssen bestimmte technische Funktionen gegeben sein, damit funktionelle und strukturelle Voraussetzungen erfüllt werden können.
Strukturelle Voraussetzungen
Um die Grundfunktion der Datenspeicherung und -verwaltung zu ermöglichen, benötigen Data Lakes zunächst Schnittstellen zu den verschiedenen Quellen der Datenströme. Folglich müssen sie auch mit den unterschiedlichen Datenformaten kompatibel sein, weshalb eine Unterstützung der gängigen Protokolle und Frameworks von Datenbanksystemen erforderlich ist.
Für die gezielte Filterung der Datenmenge bietet sich zudem die Einrichtung einer Suchmaschine an. Damit diese effektiv genutzt werden kann, müssen allerdings alle Daten mit Identifiern und aussagekräftigen Metadaten-Tags versehen werden. Diese Maßnahmen verhindern auch, dass der Data Lake zu einem Data Swamp verkommt. Zuletzt sind Mechanismen zur Sicherung und Wiederherstellung der Daten bereitzustellen, um den Verlust der kostbaren Informationen zu verhindern.
Datenschutz
Bei der Einrichtung eines Massendatenspeichers ist immer besondere Sorgfalt auf die Einhaltung von Datenschutzrichtlinien zu legen. Je größer das Volumen an zusammenhängenden Daten, desto besser sind diese zu schützen – daher erfordern Data Lakes meist ausgiebige Maßnahmen für die Gewährleistung von Datenschutz und Datensicherheit.
Bereits bei der Konzeption eines Data Lake sollte ein durchdachtes Sicherheitskonzept erstellt werden: Die Abfrage sensibler Daten ist durch eine rollenbasierte Zugangskontrolle mit unterschiedlichen Zugriffsrechten zu regulieren. Somit können Daten nur von jenen Nutzern abgerufen werden, die explizit für die Bearbeitung autorisiert wurden. Für zusätzliche Sicherheit sorgt die Verschlüsselung der Datensätze.
Mit unserer KI-Potenzialanalyse optimieren Sie Ihre Vertriebsprozesse mit Künstlicher Intelligenz und steigern Ihre Abschlussquoten.
Technische Architektur von Data Lakes
Traditionell werden Data Lakes lokal auf dem Java-basierten Open Source Framework Apache Hadoop eingerichtet. Die Implementierung erfolgt auf einem Cluster aus preiswerter Commodity-Hardware, deren Herzstück die Speicherebene namens Hadoop Distributed File System (HDFS) darstellt. HDFS ist dafür verantwortlich, die Daten auf mehreren verteilten Servern zu speichern und zu replizieren. Weitere Kernkomponenten sind der Resource Manager YARN (Yet Another Resource Negotiator) und das Programmiermodell MapReduce. Weiterhin stehen Nutzern spezielle Tools und Erweiterungen zur Aufnahme, Aufbereitung und Extraktion von Daten zur Verfügung:
- Apache Hive: Einrichtung eines Data Warehouse auf Hadoop-Basis
- Apache Sqoop: Effizienter Datentransfer zwischen Hadoop und relationalen Datenbanken
- Apache Flume: Aggregation und Transfer von Protokolldateien
- Apache Kafka: Verarbeitung von Datenströmen
- U.v.m.
Hadoop: Vor- & Nachteile
Hadoop bietet diverse Vorteile, mit denen es seine Position als Go-To-Lösung für Massendatenverarbeitung konsolidieren konnte:
- Kosten: Da ein HDFS in der Regel aus handelsüblicher Hardware besteht und Open Source Software verwendet, ist es in der Anschaffung besonders kostengünstig.
- Skalierbarkeit: Da Hadoop-Cluster leicht skalierbar sind, muss zum Zeitpunkt der Einrichtung eines Data Lake keine verbindliche maximale Speicherkapazität festgelegt werden.
- Performance: Der Datenzugriff erfolgt dank Datenlokalität besonders schnell, da die Daten direkt dort verarbeitet werden, wo sie abgelegt sind.
- Benutzerfreundlichkeit: Für das Open Source Framework existiert eine umfangreiche Auswahl an leicht verständlichen User Interfaces und hilfreichen Tools.
- Popularität: Aufgrund seiner weitverbreiteten Nutzung sind die meisten IT-Experten mit Hadoop bekannt.
Trotz der langjährigen und weitverbreiteten Nutzung von Hadoop ist es nicht für alle Nutzer und Anwendungsbereiche die optimale Lösung. Schwachstellen von Hadoop sind beispielsweise die hohe Komplexität des Systems, teils unzureichende Sicherheitsfeatures und schlechte Performance bei der Bearbeitung vergleichsweise kleiner Dateien.
Für manche Unternehmen ist es sinnvoller, alternative Lösungen für Big-Data-Analysen zu nutzen, die besser auf spezifische Anwendungsbereiche ausgelegt sind. Anderen ist der Aufwand für die Einrichtung und Instandhaltung der benötigten Infrastruktur zu groß. Dafür gibt es seit einigen Jahren auch eine Lösung: die Einrichtung eines cloudbasierten Data Lakes mithilfe eines Web Service Anbieters.
Data Lakes in der Cloud
Der Aufbau einer lokalen Data Lake Infrastruktur birgt diverse Herausforderungen. Zunächst müssen sich geeignete Räumlichkeiten für den Aufbau eines Datenzentrums finden, erforderliche Hardware muss angeschafft werden und es bedarf jemanden mit den nötigen Kenntnissen, um einen Data Lake überhaupt funktionell einzurichten und zu verwalten.
Unternehmen, die einen solchen Aufwand umgehen möchten, ohne auf die Vorteile eines Data Lake zu verzichten, haben die Möglichkeit zur Einrichtung in der Cloud. Dabei werden die nötigen Serverkapazitäten von Plattformen wie Amazon Web Services (AWS) oder Microsoft Azure zur Verfügung gestellt und gewünschte Funktionen, Erweiterungen und Tools extern eingerichtet.
Vorteile der Cloud
- Ease of Use: Durch die Bereitstellung der Software durch einen Dienstleister sind kaum Fachkenntnisse nötig und die Einrichtung kann bereits nach kurzer Zeit abgeschlossen sein.
- Kostenflexibilität: Anfallende Kosten können dank Pay-as-you-use-Preismodellen meist individuell angepasst werden
- Skalierung: Bei steigendem oder schwankendem Bedarf an Speicherplatz können Kapazitäten einfach und schnell angepasst werden.
Nachteile der Cloud
- Sicherheitsbedenken: Anbieter werben zwar mit ausgefeilten Sicherheits- und Datenschutzvorkehrungen, die externe Speicherung vertraulicher Daten ist aber immer mit gewissen Grundrisiken verbunden, die es zu berücksichtigen gilt.
- Performance: Die Geschwindigkeit von Datenzugriff und -verarbeitung können bei cloudbasierten Data Lakes je nach Auslastung des Netzwerks schwanken, sodass es bei hohem Traffic zu Verzögerungen kommt.
- Lock-in: Da durch die Einrichtung eines cloudbasierten Data Lake eine langfristige Bindung zum Anbieter entsteht, ist eine ausführliche Recherche bezüglich des Leistungsumfangs und des Preismodells zu machen. So können unangenehme Überraschungen wie versteckte Kosten vermieden werden.
Flexibilität in der Auslagerung
Data Lakes bestehen aus zwei Komponenten: Speicher und Verarbeitung. Je nach Bedarf bietet es sich an, nicht die gesamte Infrastruktur, sondern nur einzelne Teile dieser Komponenten in der Cloud unterzubringen. Zwischen einer komplett lokalen Infrastruktur und der gesamten Auslagerung in die Cloud gibt es also Möglichkeiten für den Aufbau hybrider Modelle. Damit kann ein System aufgebaut werden, dass die Vorteile der Cloud nutzt und gleichzeitig mögliche Nachteile umgeht, um so die größtmögliche Wertschöpfung zu ermöglichen.

Zusammenfassung
Ein Data Lake bietet unvergleichliche Möglichkeiten für die massenhafte Speicherung, Verarbeitung und Analyse heterogener Rohdatenformate im Big Data-Bereich. Die Einrichtung eines Data Lake ergänzend zu einem Data Warehouse kann sinnvoll sein, wenn eine Vielzahl unstrukturierter Daten anfällt oder bisherige Analyseverfahren ausgeweitet werden sollen.
Aufbau und Instandhaltung eines Data Lake sind allerdings mit relativ hohem Aufwand verbunden und setzen ein gewisses Expertenwissen voraus. Besonders wichtig sind dabei Maßnahmen für die Aufrechterhaltung der Datenqualität, da der Data Lake sonst zu einem Datensumpf verkommen kann. Auch das Thema Datenschutz muss berücksichtigt werden, wenn es zur Ablage vertraulicher Informationen kommt.
Der Aufbau von Data Lakes kann lokal, in der Cloud, oder sogar als Hybridmodell stattfinden. Die Wahl sollte individuell je nach Bedarf getroffen werden, da es unterschiedliche Vor- und Nachteile mit sich bringen kann. Ungeachtet dessen können die meisten Unternehmen durch eine fachgerechte Einrichtung und Nutzung eines Data Lakes echte Wettbewerbsvorteile erringen.
Dieser Artikel erschien bereits am 09.12.2020. Der Artikel wurde am 01.09.2025 erneut geprüft und mit leichten Anpassungen aktualisiert.
FAQ
Was ist ein Data Lake und wofür wird er eingesetzt?
Ein Data Lake ist ein zentrales Repository zur Speicherung großer Mengen an Rohdaten in verschiedensten Formaten. Anders als ein Data Warehouse speichert er Daten in ihrer ursprünglichen, oft unstrukturierten Form und eignet sich besonders für vielfältige Analysezwecke wie Visualisierungen, Berichte, Echtzeitanalysen oder Machine Learning.
Welche technischen und organisatorischen Voraussetzungen sind für die Nutzung eines Data Lakes erforderlich?
Damit ein Data Lake zuverlässig funktioniert, muss er verschiedene Datenquellen und -formate unterstützen – etwa strukturierte Datenbanksätze oder Echtzeitdaten aus dem Internet of Things. Voraussetzung dafür sind kompatible Schnittstellen, gängige Protokolle sowie Tools für Analyse, Suche und Datenmanagement. Um Ordnung in den Datenbestand zu bringen, sind Metadaten-Tags und Identifier essenziell. Ebenso wichtig sind Backup-Mechanismen sowie ein durchdachtes Sicherheitskonzept: Rollenbasierte Zugriffsrechte und Verschlüsselung sorgen für Datenschutz und verhindern unautorisierten Zugriff auf sensible Informationen.
Welche Vorteile bietet Hadoop im Zusammenhang mit Data Lakes?
Hadoop überzeugt durch eine Reihe praktischer Vorteile für die Massendatenverarbeitung in Data Lakes. Dank der Nutzung handelsüblicher Hardware und Open-Source-Software ist es besonders kosteneffizient. Die Architektur ist flexibel skalierbar, sodass keine feste Speichergrenze definiert werden muss. Durch Datenlokalität ist der Datenzugriff sehr performant. Zudem profitieren Nutzer von einer Vielzahl benutzerfreundlicher Tools und Interfaces – und dank der weiten Verbreitung ist Hadoop vielen IT-Fachkräften bereits vertraut.








