

Im telefonischen Kundenportal, beim Gespräch mit dem Smartphone-Assistenten oder während einer Bahnhofsdurchsage – Text-To-Speech ist heutzutage vielerorts im Einsatz. Es wird überall da genutzt, wo textbasierte Informationen über eine künstlich erzeugte Sprachausgabe wiedergegeben werden. So wird die Bedienung von und Kommunikation mit verschiedensten Systemen erleichtert.
Was ist Text-To-Speech (TTS)?
Als Text-To-Speech bezeichnet man die Erzeugung von gesprochener Sprache mit technischen Mitteln basierend auf Texteingaben. Grundsätzlich wird bei der künstlichen Spracherzeugung zwischen Methoden der Sprachwiedergabe und Sprachsynthese unterschieden.
Die Sprachwiedergabe greift auf zuvor eingesprochene Aufnahmen zurück, die dann mithilfe von Signalmodellierung an den Kontext angepasst werden. Dagegen wird die artikulatorische Sprachsynthese genutzt, um Texteingaben per Computergenerierung und ohne Nutzung von Audiosamples in akustische Sprachausgaben umzuwandeln. In professionellen TTS-Systemen wird heutzutage vorwiegend Methoden der Signalmodellierung angewendet undzunehmend durch Deep-Learning-Modelle ergänzt. Neurale TTS-Systeme können dabei Prosodie, Emotion und sogar individuellen Sprechstil nachbilden, was die Sprachausgabe erheblich natürlicher wirken lässt.
Funktionsweisen von TTS-Systemen
Ein Text-To-Speech-System besteht hauptsächlich aus zwei Komponenten: der NLP-Komponente (Natural Language Processing), welche den ausgewählten Text analysiert und phonetisch interpretiert, und der DSP-Komponente (Digital Signal Processing), welche das akustische Sprachsignal erzeugt.
NLP-Komponente
Mithilfe der NLP-Komponente (Natural Language Processing) wird der Text in seine phonetische Repräsentation umgewandelt. Dafür wird die gesamte Zeichenkette in einzelne Tokens oder Laute aufgeteilt und gemäß einem zugrundeliegenden Regelwerk oder Lexikon prozessiert. Dadurch werden Aussprache, Betonung und Satzmelodie (genannt Prosodie) korrekt ermittelt, sodass anschließend eine flüssige und natürlich klingende Lautfolge erzeugt werden kann.
DSP-Komponente
Die DSP-Komponente (Digital Signal Processing) ist für die eigentliche Generierung der Lautfolge zuständig. Dafür kommen zwei unterschiedliche Ansätze in Frage: die artikulatorische Synthese, welche die menschliche Lauterzeugung maschinell zu imitieren versucht, und die Signalmodellierung, welche zuvor aufgezeichnete Signale modifiziert und kombiniert. Die praktischen Methoden beider Ansätze haben gemein, dass sie auf Datenbanken zurückgreifen, in denen charakteristische Informationen über Sprachsegmente hinterlegt sind. Diese werden dann für die Erzeugung der gewünschten Äußerungen miteinander verknüpft. Je größer die Datenbank, desto mehr Laute werden erfasst. Dadurch ist weniger Nachbearbeitung nötig und das Resultat klingt authentischer.
DSP: Artikulatorische Synthese
Dieser Ansatz zielt darauf ab, den organischen Artikulationstrakt des Menschen – also Lungen, Lippen, Zunge, etc. – mechanisch nachzubilden, um so sämtliche menschliche Lautäußerungen erzeugen zu können. Dadurch ließe sich ein quasi unbegrenzter und natürlich klingender Wortschatz erreichen. Die Umsetzung eines solchen Modells ist jedoch mit enormem Aufwand verbunden. Aus diesem Grund ist der Ansatz der artikulatorischen Synthese für kommerzielle TTS-Anwendungen ungeeignet und wird eher für experimentelle Zwecke genutzt.
Verschaffen Sie sich effizienteren Zugang zu Unternehmenswissen und optimieren Sie die Kommunikation mit einem eigenen KI-Assistenten.
DSP: Signalmodellierung
Im Gegensatz zur artikulatorischen Synthese konzentriert sich der Ansatz der Signalmodellierung nicht auf die Lauterzeugung selbst, sondern auf die Veränderung bereits bestehender sprachlicher Signale. Hierbei werden im Voraus aufgenommene Sprachsamples aufbereitet, indem die Aufnahmen aneinandergereiht und Tonlage, Intonation und Satzmelodie angepasst werden. Dadurch lassen sie sich in verschiedenen Kontexten nutzen, ohne dabei allzu befremdlich zu klingen.
Umsetzung
Die eigenständige Entwicklung und Umsetzung eines TTS-Systems kann je nach angestrebtem Funktionsumfang ein äußerst umständliches Vorhaben sein. Simple Telefonbandansagen sind z.B. noch relativ unkompliziert realisierbar. Intelligente und flexible Systeme erfordern allerdings die Programmierung komplexer Anwendungen und den Einsatz von künstlicher Intelligenz und Machine Learning. Mit Technologien wie Deep Learning basierend auf Neuronalen Netzen kann das System den eigenen Wissensbestand selbstständig erweitern und Kundenanfragen dynamisch und zuverlässig bearbeiten.
Glücklicherweise gibt es eine heutzutage Reihe von Webservice-Angeboten wie z.B. Amazon Polly, die vorgefertigte Lösungen bereitstellen, um den Aufwand für die Einrichtung im eigenen Unternehmen zu minimieren.
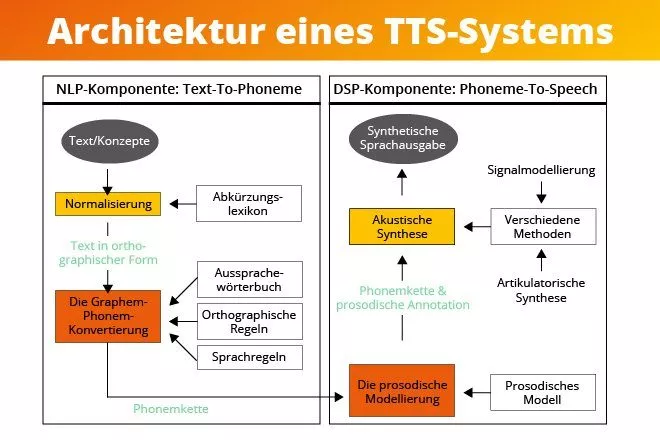
NLP- & DSP-Komponente eines TTS-Systems
Herausforderungen
Seit ihrer Konzeption sehen sich TTS-Systeme mit der schwierigen Aufgabe konfrontiert, natürliche Sprache zu verarbeiten und darüber hinaus noch lautsprachlich korrekt auszugeben. Aufgrund der Komplexität und Vielfältigkeit menschlicher Sprache ergeben sich daraus diverse Hindernisse. Bis vor Kurzem konnten TTS-Systeme diese Hürden kaum bewältigen, weshalb computergenerierte Lautfolgen meist robotisch und unnatürlich wirkten. Heutige realistisch klingende Systeme zeichnen sich dadurch aus, dass sie diese Herausforderungen mithilfe moderner Technologien überwinden können:
Textnormalisierung
- Korrekte Wiedergabe von Homographen (identisch geschriebene Wörter mit unterschiedlichen Bedeutungen)
- Differenzierung von Zahlenwerten (1903 – Neunzehnhundertdrei, Eintausendneunhundertdrei oder eins neun null drei)
- Erkennen und Angleichen von Abkürzungen (tgl. – täglich, tägliche, täglicher, täglichen)
Heuristische Verfahren
- Nutzen geeigneter Methoden zur Ermittlung korrekter Wortbedeutungen (bspw. mittels Untersuchung benachbarter Wörter)
Text-zu-Phonem
Zwei Ansätze zur Ermittlung der Aussprache eines Wortes auf Grundlage der Schreibweise (meist in Kombination eingesetzt):
- wörterbuchbasiert: Abfrage der auszusprechenden Wörter aus einem Wörterbuch
- schnell und genau, versagt bei unbekannten Wörtern, hoher Speicherplatzbedarf (sinnvoll z.B. im Deutschen & Englischen)
- regelbasiert: Anwendung von Ausspracheregeln ausgehend von Schreibweise
- funktioniert bei unbekannten Wörtern, erhebliche Komplexität des Regelsatzes bei unregelmäßiger Schreibweise/Aussprache (sinnvoll z.B. im Spanischen & Französischen)
High-Fidelity-Sprache
- Angleichung beim Aneinanderketten von Lautsegmenten durch Korrekturen in Lautstärke, Grundfrequenz und Betonung
- Identifizierung stimmlicher Merkmale bei emotionalen Inhalten für Verbesserung der Natürlichkeit künstlich synthetisierter Sprache

Use Cases
Ursprünglich wurde computergenerierte Sprachsynthese genutzt, um die Kommunikation von Menschen mit Seh- und Sprachbehinderungen mit ihrer Umwelt zu vereinfachen – ein nach wie vor zentrales Einsatzgebiet von TTS-Systemen. Heutzutage wird künstliche Sprachsynthese sogar eingesetzt, um Sprachwissenschaftler bei der Analyse von Sprachstörungen zu unterstützen.
Durch die kontinuierliche Weiterentwicklung hat sich die Qualität von TTS-Systemen in den letzten Jahren jedoch derart verbessert, dass Sprachsynthese für immer mehr Anwendungsfälle an Nutzen gewinnt. Besonders in Situationen, in denen kein geeignetes Display zur Verfügung steht oder bei denen die Augen mit anderen Aufgaben beschäftigt sind, wird Text-To-Speech für die Bedienung von Anwendungen genutzt. Dies spiegelt sich in der steigenden Nachfrage und dem stetig wachsenden Markt für TTS- und Spracherkennungslösungen wider.
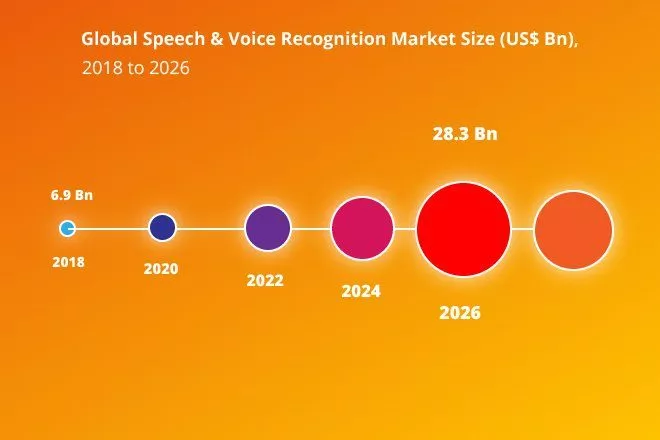
Marktvolumen von TTS & Spracherkennung
TTS-Systeme lassen sich besonders in Kombination mit Spracherkennung und Speech-To-Text-Software für eine Vielzahl von Anwendungen in verschiedensten Branchen einsetzen. Nachfolgend eine ausschnitthafte Übersicht beliebter Use Cases:
- Barrierefreiheit: Um Websites, Anwendungen und Dienstleistungen für Menschen mit Seh- oder Leseschwächen leichter zugängig zu machen, können ihre Textinhalte durch eine digitalen Sprachausgabe ergänzt und somit nutzerfreundlicher gemacht werden.
- Gesundheitswesen: Geräte zum Monitoring des Gesundheitszustands können Sprachsynthese nutzen, z.B. um Benachrichtigungen über auffällige Herzfrequenzen oder Blutzuckerwerte zu verbalisieren.
- IT & Telekommunikation: TTS ermöglicht schnellen, mehrsprachlichen und personalisierten Service bzw. First-Level-Support und hilft dabei, dass die Auslastung auch in Stoßzeiten die verfügbaren Kapazitäten nicht übersteigt.
- Automobilindustrie: In Fahrzeuge integrierte elektronische Interfaces und Navigationssysteme profitieren davon, ihre Bedienbarkeit ohne visuelle Ablenkung zu erlauben.
- Buchungen: Die Kopplung von TTS mit Spracherkennung bietet sich in Auskunftsystemen bspw. bei Hotelreservierungen an, um automatisch Angebote vorzustellen und Buchungsvorgänge abzuwickeln.
- Handel: Automatisierte Systeme erleichtern das Abwickeln von Bestellprozessen und die Nachverfolgung von Lieferungen.
- Finanzdienstleistungen: Banken können ihren Kunden leicht bedienbare multifunktionale Servicepunkte mit Echtzeit-Informationen bereitstellen, bspw. um Mobile Banking oder Aktienhandel bequemer zu gestalten.
- Dialogsysteme: Dynamisch generierte Sprache kann in IVR-Dialogsystemen (Interactive Voice Response) genutzt werden, um einfache Kundenanfragen flexibel zu bearbeiten, ohne dass die Aufmerksamkeit eines Mitarbeiters erforderlich ist.
- Marketing: Der Einsatz einer professionellen und individuellen Stimme erhöht den Erkennungswert Ihrer Marke und steigert das Nutzerengagement auf ihren Marketing-Kanälen.
- Internet of Things: IoT-Geräte können mit einer Stimme ausgestattet werden, um Nutzern so eine einfache, natürliche Art der Kommunikation und Bedienung zu bieten.
- Bildung: TTS wird zunehmend für die Vertonung von eLearning-Anwendungen eingesetzt. Hier können Autoren selbstständig softwaregenerierte Vorträge ihrer Lernunterlagen erstellen, sodass die Vertonung den Lernenden unverzüglich bereitgestellt werden kann.
- Unterhaltung: TTS wird genutzt, um Dialoge und Narrationen in Videospielen oder Animationsprojekten zu erzeugen. Weiterhin können Online-Texte wie Blogbeiträge oder eBooks vertont werden, um sie als Podcasts oder Audioblogs abspielbar zu machen.
- Personal Assistants: Chatbots und persönliche Sprachassistenten wie Alexa und Siri nutzen das Zusammenspiel von NLP, Spracherkennung und Text-To-Speech, um eine intuitive Verbindung zu Nutzern herzustellen und diverse Alltagsaufgaben zu übernehmen.
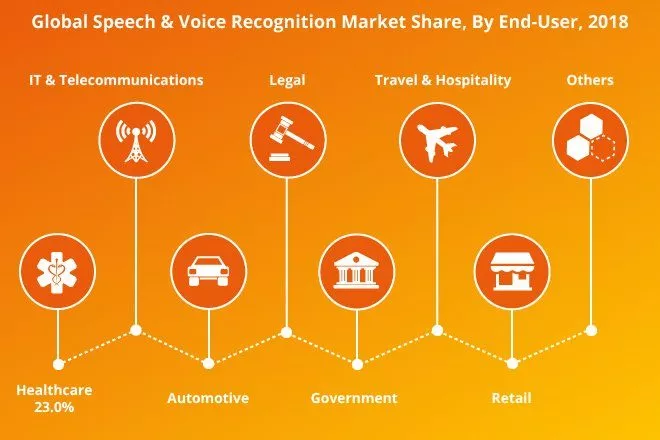
In diesen Branchen werden TTS & Spracherkennung am meisten genutzt.
Vorteile
Die Ergänzung von Produkten, Geräten oder Dienstleistungen mit Text-To-Speech bringt diverse Vorteile mit sich, insbesondere da die Einrichtung eines vorgefertigten TTS-Systems sehr simpel ist. Ein Überblick der wichtigsten Vorteile:
- Reichweitenerhöhung: Inhalte werden einem größeren Publikum zugänglich gemacht und lassen sich leicht in mehrere Sprachen übersetzen.
- Kostenreduzierung: Automatisierung von Anrufabwicklungen spart Ressourcen langfristig.
- Verbesserung von Kundeninteraktion: Intelligente Anfragenbearbeitung liefert höchste Benutzerfreundlichkeit über mehrere Kunden-Touchpoints.
- Ansprechender Service: Stimme und Sprache können personalisiert und an ausgewählte Zielgruppen angepasst werden.
- Markenwahrnehmung: Abheben von der Konkurrenz durch eine einzigartige Stimme mit Wiedererkennungswert.

Eine Stimme für Ihre Marke
Wenn Sie und Ihr Unternehmen von den Vorteilen eines Text-To-Speech-Systems profitieren möchten, stehen wir Ihnen gerne für eine unverbindliche und kostenlose Erstberatung zur Verfügung. Unsere Consultants unterstützen Sie beim Prozess der Auswahl und Implementierung, sodass Ihr Unternehmen ein TTS-System erhält, das auf Ihre Wünsche und Anforderungen zugeschnitten ist.
Dieser Artikel erschien bereits am 30.09.2021. Der Artikel wurde am 01.09.2025 erneut geprüft und mit leichten Anpassungen aktualisiert.
FAQ
Was versteht man unter Text-To-Speech?
Text-To-Speech bezeichnet den Prozess, textbasierte Informationen per künstlicher Spracherzeugung hörbar wiederzugeben. TTS wird oftmals in Kombination mit Spracherkennung eingesetzt, um die Interaktion mit Kommunikationssystemen zu erleichtern.
Wie funktioniert Text-To-Speech?
Kommerzielle Systeme arbeiten meist mit einer Vielzahl einzelner Sprachaufnahmen, die dem Kontext entsprechend aneinandergekettet und modelliert werden, um so eine natürlich klingende Sprachausgabe zu erzeugen.
Wie integriere ich Text-To-Speech in mein Produkt/meine Dienstleistung?
Es gibt eine Vielzahl von Entwicklungsmethoden, die sich für unterschiedliche Einsatzmöglichkeiten eignen. Diverse Webservice-Anbieter stellen vorgefertigte und leicht integrierbare TTS-Systeme zur Verfügung. Unsere Berater helfen Ihnen, einen Überblick zu erhalten.
Wo wird Text-To-Speech eingesetzt?
Da TTS-Systeme grundsätzlich zur Verbesserung der Bedienbarkeit dienen, können sie in verschiedensten Branchen sinnvoll genutzt werden. Beliebt ist der Einsatz von TTS in Dialogsystemen wie Support- und Kundenservice-Portalen, bei der Nutzung von smarten Geräten oder allgemein zur Bereitstellung barrierefreier Inhalte.
Wer kann mir beim Thema Text-To-Speech (TTS) helfen?
Wenn Sie Unterstützung zum Thema Text-To-Speech (TTS) benötigen, stehen Ihnen die Experten der mindsquare AG zur Verfügung. Unsere Berater helfen Ihnen, Ihre Fragen zu beantworten, das passende Tool für Ihr Unternehmen zu finden und es optimal einzusetzen. Vereinbaren Sie gern ein unverbindliches Beratungsgespräch, um Ihre spezifischen Anforderungen zu besprechen.








