
Bestärkendes Lernen – ein Agent löst Ihre KI-Probleme

Wäre es nicht schön, für Künstliche Intelligenz (KI) einen Agenten zu beauftragen, der Ihnen bei der Arbeit hilft? So (oder eher so ähnlich) funktioniert bestärkendes Lernen oder auch Reinforcement Learning. Das ist ein Teil von Machine Learning und lernt im Gegensatz zu vielen anderen Modellen nicht aus vorhandenen Daten, sondern generiert Lösungen selbst. Wie genau das funktioniert, erkläre ich in diesem Beitrag.
Sie benötigen keine historischen Daten
Möglicherweise kennen Sie schon die klassische Funktionsweise von Machine Learning. Grob überschlagen: Das KI-Modell wird mit historischen Daten bespielt und wird mit diesen trainiert. Die KI leitet daraus dann Muster ab und kann auf dieser Basis Entscheidungen oder Prognosen treffen. Dafür gibt es verschiedene Umsetzungsformen, beispielsweise Random Forests oder Support Vector Machines.
Im Gegensatz dazu benötigt die Methode des bestärkenden Lernens keine historischen Daten. Sie können sich das ungefähr so vorstellen, als würden Sie eine Maschine (einen Agenten) selbständig und ohne Datenbasis an einem Problem arbeiten und herumprobieren lassen, bis dieser Agent das Problem lösen kann. Der Begriff Agent ist dabei natürlich als fiktive Instanz gedacht, nicht etwa als reale Person.

Sie möchten wiederkehrende Aufgaben, Anfragen und Entscheidungen nicht länger manuell abarbeiten? Wir entwickeln einen KI-Agenten, der Informationen beschafft, Aufgaben vorbereitet, Prozesse anstößt und Ihr Team im Tagesgeschäft wirksam entlastet – sauber integriert in Ihre bestehende IT-Landschaft.
Bestärkendes Lernen kommt also dann zum Einsatz, wenn das Ziel bereits bekannt ist, der Weg dahin allerdings nicht. Wenn zum Beispiel für einen Weg der Startpunkt und das Ziel bekannt sind, der schnellste Weg dahin allerdings nicht, wird durch eine Simulation mit dem Trial-and-Error-Verfahren der schnellste Weg ermittelt.
Was genau macht der Agent?
Anders als beim Lernen aus historischen Daten bekommt der Agent zunächst keine Angaben vom Entwickler, wie er sich verhalten soll. Daraufhin trainiert sich die KI quasi selbst durch ein Trial-and-Error-Verfahren. Das funktioniert folgendermaßen (siehe Abbildung): Der Agent agiert in einer gewissen Art und Weise und führt eine Aktion durch, die seine Umwelt beeinflusst. Dadurch bildet sich ein Folgezustand, der wiederum an den Agenten zurückgemeldet wird.
Während des Übergangs in den Folgezustand erhält der Agent außerdem eine Belohnung. Damit sind nicht nur positive, sondern auch negative Rückmeldungen auf sein Handeln gemeint. Die Gewichtung dieser Belohnungen legt dabei der Entwickler fest, sodass das Verhalten des Agenten auch das richtige Ziel verfolgt.
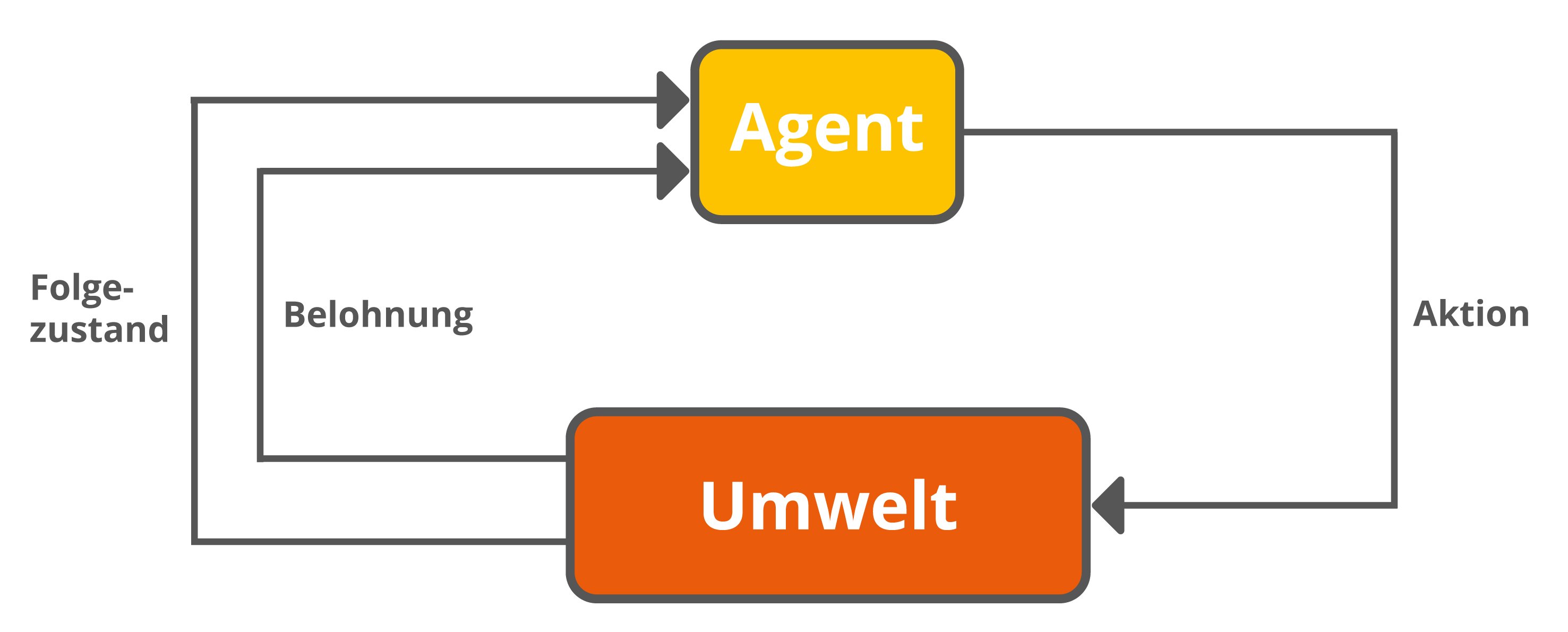
Trial-and-Error-Verfahren
Der Agent lernt nun dazu, indem er aufgrund der Belohnungen entscheidet, ob seine zuvor durchgeführte Aktion richtig oder falsch war. Die Strategie für sein Verhalten wird also schrittweise verbessert. Das Ziel des Agenten ist es, eine Vorgehensweise zu erlernen, die die positiven Belohnungen maximiert. Die Maschine lernt also genauso wie der Mensch. Wenn ich etwas gut mache und dafür belohnt werde, wiederhole ich es. Mache ich etwas falsch, werde ich es in Zukunft vermeiden.

Diese Vorteile hat bestärkendes Lernen
Gegenüber anderen Methoden des Machine Learning hat bestärkendes Lernen den großen Vorteil, nicht auf einer vorher bestehenden Datenbasis agieren zu müssen. Sie können also ohne menschliches Vorwissen komplexe Probleme lösen. Das Lernverfahren ähnelt, wie eben beschrieben, sehr dem natürlichen Lernprozess beim Menschen, die KI kann durch die maschinelle Power aber deutlich komplexere Lösungen erarbeiten.
Ein weiterer Vorteil: Das bei anderen Verfahren so aufwendige Training der KI auf der Grundlage von historischen Daten fällt komplett weg. Die KI trainiert beim bestärkenden Lernen nämlich durch die eigene Erfahrung. Der Mensch muss also über den gesamten Zeitraum keine Lösungen vorgeben, da das System von selbst lernt. Das führt dazu, dass auch komplett neue Lösungen, an die der Mensch vorher nicht gedacht hat, entwickelt werden können. Das kann dann sogar so weit reichen, dass die Maschine am Ende schlauer agiert, als der Mensch – dazu aber gleich noch mehr.
Ist das für mich nutzbar?
Grundsätzlich eignet sich bestärkendes Lernen dazu, komplexe Steuerungsprobleme ohne menschliches Vorwissen zu lösen. Doch es ist natürlich – wie eigentlich alle KI-Methoden – nicht für jedes Problem anwendbar, sondern nur für bestimmte Anwendungsfälle. Wenn Sie herausfinden wollen, ob bestärkendes Lernen bei Ihrem Use Case Sinn ergibt, sollten Sie sich folgende Fragen stellen:
- Kann ich ein Trial-and-Error-Verfahren anwenden?
- Handelt es sich um ein Steuerungs- oder Kontrollproblem?
- Ist die Aufgabe simulierbar?
- Kann ich den Status jederzeit erfragen und ändern?
- Ist kein Einsatz von anderen Methoden möglich?
Sollten Sie sich einige dieser Fragen mit Ja beantworten können, bietet sich der Einsatz von bestärkendem Lernen an.
Wenn KI unbesiegbar wird
Damit Sie ein Bild davon bekommen, wie das Ganze dann in der Praxis aussehen kann, möchte ich nun einmal auf ein Anwendungsbeispiel eingehen. Wie bereits oben angesprochen, wird die KI möglicherweise mit der Zeit schlauer als der Mensch. So geschehen beim Brettspiel Go: Dort wurde mit dem Programm AlphaGo und dem Nachfolger AlphaGo Zero eine KI entwickelt, die für den Menschen quasi unschlagbar ist.

Das geschah durch bestärkendes Lernen. Ganz zu Beginn wurde der KI nur ein Spielfeld mit weißen und schwarzen Steinen vorgelegt und die Regeln wurden festgelegt. Die KI spielte dann gegen sich selbst und entschied durch Algorithmen über den nächsten Zug. Für Siege wurde sie mit Punkten belohnt. Daraus entwickelte die KI eine Strategie und fand Wege, die selbst die besten Spieler der Welt zuvor nicht kannten. AlphaGo hat bereits Weltmeister mehrfach geschlagen, AlphaGo Zero hat dann seinen Vorgänger 100:0 besiegt und ist damit nahezu unschlagbar.
Generell ist die Spielewelt sehr gut geeignet für die Entwicklung von KI durch bestärkendes Lernen – egal ob Video- oder Brettspiel. Es ist dort meist klar definiert, welches Verhalten richtig und welches falsch ist und es können leicht Belohnungen ausgesprochen werden.
Die KI trainiert sich selbst
An dem Beispiel AlphaGo Zero wird deutlich: Die KI schafft es mit bestärkendem Lernen, sich selbst zu trainieren und immer weiter zu verbessern. Die menschlichen Eingriffe sind nach dem Start nicht sonderlich groß, Sie müssen lediglich die Anfangsumgebung und die Belohnungen festlegen. Dann entwickelt die KI möglicherweise Lösungen, die Sie jetzt vielleicht noch gar nicht kennen.

Verwandte Beiträge







